X.25 Stress Test
X.25 Stress Test
I have built a small collection of hardware and software for exploring X.25 networking. It contains routers, interfaces and bridges from the 1990s through to the early 2020s.
Welcome to my Lab has an introduction to the various devices discussed below.
The Problem
I have created a new software X.25 router implementation, and would like to verify that it is perfomant and stable. I also wanted to verify that data makes the round trip without modification or session confusion.
Tooling
I asked Gemini to write an X.25 stress test tool in C to my specification. I stuck with basic packet and window sizes, ignoring extended sizes for now. We can extrapolate the effect of increasing packet and window sizes from the graphs below.
The sender initiates connections:
- Multi-threaded Sender: Simulate high load with multiple threads.
- Facility Negotiation: Negotiate window and packet sizes.
- Randomized Calling: Call random X.121 addresses within a range.
- Data Verification: Each call randomly sends 1-8192 bytes of data, which is reflected back and verified on receipt using weakly unique data patterns.
- Detailed Reporting: Reports min/max negotiated facilities, bandwidth, and failures.
In receive mode the tool accepts calls and echos data back to the sender.
Stress test has per thread penalties for certain behaviours, in case misconfigurations or resource constraints are hit:
- Failing to open a socket will be logged cause a 1 second sleep.
- Failing to bind a local address or connect to a remote address will be logged and cause a configurable (default 1 second) sleep.
- The receive timeout is 5 seconds, so lost packets cost 5 seconds.
The stress test source code is checked into goxot.
Setup
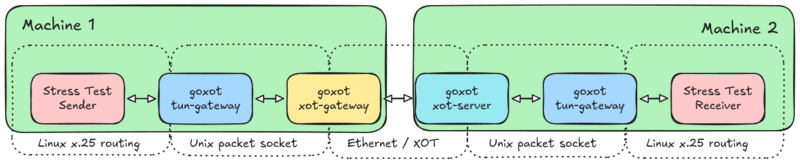
I’m testing between two machines:
 Stress Test Setup)
Stress Test Setup)
Machine 1
- Interface with local X.25 processes:
sudo go run cmd/tun-gateway/main.go -config ../config.json -stats-port 8000 - Bridge X.25 traffic out over XOT:
go run cmd/xot-gateway/main.go -config ../config.json -stats-port 8001
Machine 2
- Bridge XOT traffic to local X.25:
go run cmd/xot-server/main.go -config ../config.json -stats-port 8001 - Interface with local X.25 processes:
sudo go run cmd/tun-gateway/main.go -config ../config.json -stats-port 8000 -tun tun0 - Listen for stress test traffic:
./stress_test -r -a 127800 -W 7 -P 4096
Here’s what a run looks like on machine 1:
stress_test -N 4 -l 8192 -d 127800,127800 -T 20 -n 20000 -a 127111 -b 50 -W 3 -P 4096
Thread 1: Short receive: expected 1317, got 0
--- Stress Test Summary ---
Run Time: 19.93 seconds
Calls Made: 9835
Calls Received: 0
Calls Failed: 0
Packets Sent: 9832
Packets Received: 9831
Bytes Sent: 40080284
Bytes Received: 40078968
Data Mismatches: 1
Packet Size Negotiated (In): Min: 4096, Max: 4096
Packet Size Negotiated (Out): Min: 4096, Max: 4096
Window Size Negotiated (In): Min: 3, Max: 3
Window Size Negotiated (Out): Min: 3, Max: 3
Average Bandwidth (Sent): 1963.59 KB/s
Average Bandwidth (Recv): 1963.52 KB/s
---------------------------Performance
In the stress test, X.25 packet and window size is configurable, as is the maximum volume of data to send/receive.
- Packet size: Data is broken down into packets that can carry this much data.
- Window size: After sending this much data, stop and wait for acknowledgement before sending more. Resend the data if acknowledgement does not arrive.
The amount of data that a sender have in flight before stopping to wait for acknowledgement is packet size X window size.
The kernel fragments large sends into multiple X.25 packets with the M (more) bit set. Stress test defaults to a buffer size of 8192 bytes. If you send more than this it will be truncated by the receiver’s read() call unless the receiver also has a larger buffer size (-l 65536). The kernel has a 64KB limit (by default?) that is shared across the socket, you’ll start getting short reads at about 58KB in practice.
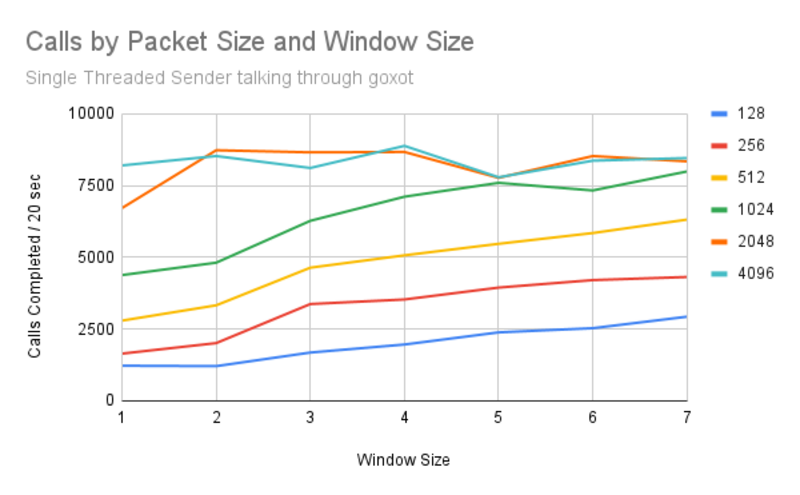 Single threaded call volume by packet/window size
Single threaded call volume by packet/window size
Looking at the single threaded graph, which shows how many calls are completed for one thread over 20 seconds, we can see a few things:
- Packet sizes 128 through to 1024 generally dont encounter limits passing through the test setup, the graphs are up and to the right as we increase packet and window sizes.
- Increasing packet and window sizes no longer improves performance once the whole message fits into the window. Our average message size is 4KB (randomly distributed between 1-8912 bytes), therefore we lose most of the benefit of increased window sizes once we can send more than 4KB without acknowledgement. This is visible on the graph as relatively flat performance beyond 1024 byte packets with a window size of 5. Being able to send the whole message without waiting for acknowledgements means filling the pipe without round trips slowing us down.
- 2048 byte packets see better performance for a window size increase from 1 to 2, but not after that (2 x 2048 = 4096 bytes in flight).
- There’s a small performance dip for larger (2048, 4096) byte packets with a window size of 5 compared to window size 4 or 6. This was reproducable across multiple runs, so it is meaningful. It’s possibly related to acknowledgements and the maximum message size (8192 bytes). Flushing through a few small packets after each message would probably reduce latency by filling the window packet count.
Once we reach about 8,000 calls per 20 seconds (~400 calls per second) we hit an unidentified performance barrier. At that point we’re doing about 1.75MB/s (14Mb/s in megabits/second).
That said, 14Mb/s is more than enough to fill a serial or ISDN link for later testing (which run at 2.048Mb/s, about 7x slower.
Let’s look at performance when multiple connections are competing for resources:
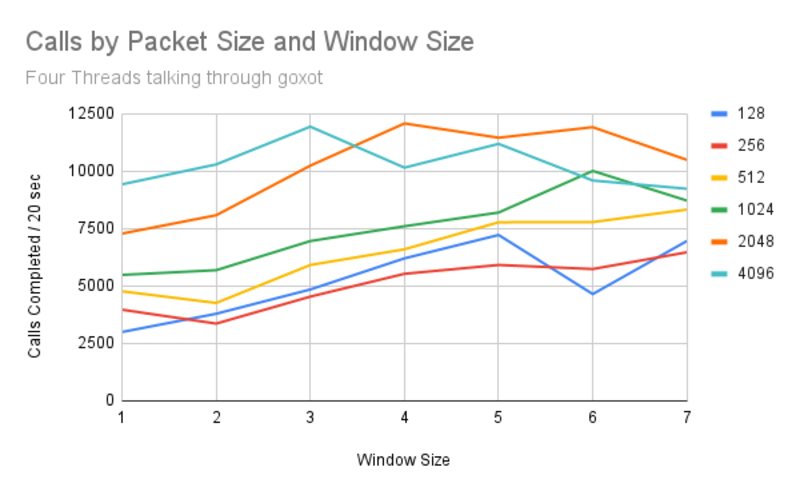 Four thread call volume by packet/window size
Four thread call volume by packet/window size
The graphs are all over the place. 128 byte packets get slightly better performance than 256 byte packets, which is surprising. There are unexplained and repeatable dips in performance with some window sizes. Overall call rate only reaches about 12,500 calls per 20 seconds (~625 calls/sec) for a throughput of close to 2.5MB/s (20Mb/s).
We will look at some bugs that may be related to this messy graph in later posts.
Problems Found
As soon as you introduce a new test, you find new problems. The tool uncovered some minor problems with itself, goxot, jh-xotd and the Linux kernel.
Problems with goxot
Testing resulted in improvements across the goxot stack. The most notable was that goxot circuits were not shut down properly, leaking LCIs which quickly lead to failure (since we only have up to 4096 LCIs).
Problems with stress test
With sufficient threads, the stress test creates situations where it tries to write to a socket that has already been closed (usually by the other end). This results in a SIGPIPE signal, which kills the process unless a handler has been defined.
We just need to ignore SIGPIPE, other code will notice that the socket is closed and handle it: signal(SIGPIPE, SIG_IGN);
Problems with xotd (and jh-xotd)
xotd and jh-xotd are also affected by the SIGPIPE issue. It’s easy to fix there as well (ignore the signal).
I won’t publish perfomance numbers here because I’ve not looked at tuning the call and data plane pathways for xotd.
Problems with the Linux x25 module
Stress test also uncovered problems in the Linux X.25 kernel module, which will be the subject of another post.
Summary
- I was expecting lots of problems and show stoppers since this is a new kind of stress test, and was pleasantly surprised.
- For best performance, consider how much data you are likely to send in one message, on average, and size your windows slightly above that.